
Hugo + Stork
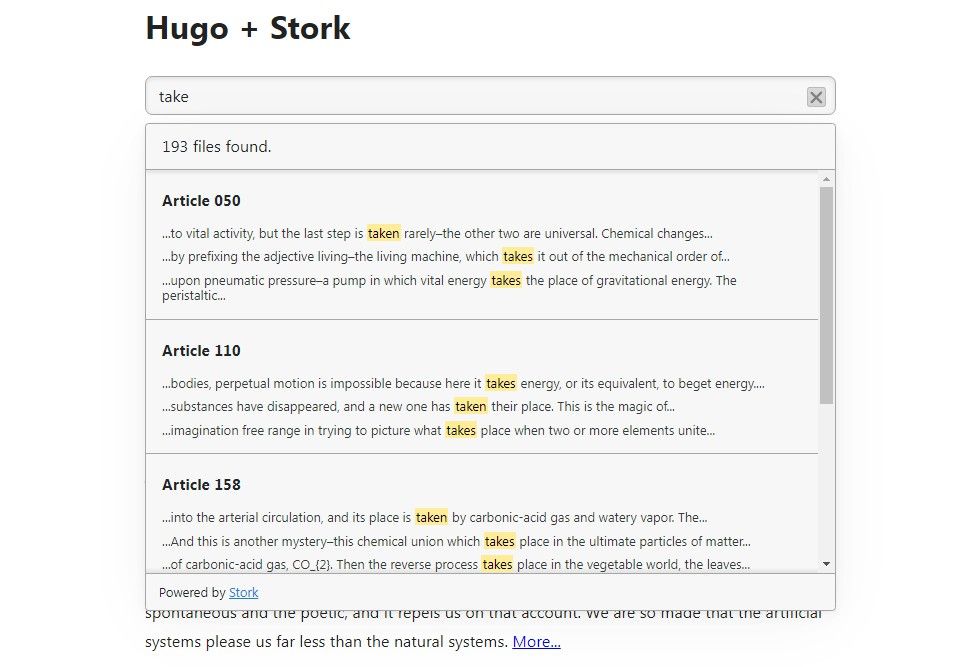
This site is built with Hugo and includes the Stork library for full-text search. The site contains 500 articles with an average of 520 words per article.
Live test sites
- Hosted by GitHub: https://jmooring.github.io/hugo-stork/
- Hosted by Netlify: https://hugo-stork.netlify.app
Test locally on Ubuntu
./build.sh
hugo server --renderToDisk
Notes
Stork generates a binary index file. With this test site, the index file is 6 MB. To force hosts such as GitHub Pages or Netlify to compress the file, we give it a json extension. We could use html or css instead, but json seemed like a better fit.
GitHub pages uses gzip compression, producing a 2.3 MB index file.
Netlify uses Brotli compression, though not aggressively, producing a 2.1 MB index file.
If you have a host that can serve pre-compressed assets, aggressive Brotli compression produces a 1.5 MB file.
Bag of bytes
When examining the page load, you can see that the browser downloads some of the assets in parallel. I ran some experiments, using a large image, to see if there would be any benefit to splitting the Stork index into pieces.
Spoiler alert: splitting the image into chunks does not improve performance.
https://hugo-stork.netlify.app/tests/
Large image:
- A single image
- 5,736,890 bytes
- 4032×2268
Large image (2 chunks):
- The same image, split into 2 chunks
- 6,002,033 bytes total
- Each chunk (tile) is 4032×1134
Large image (9 chunks):
- The same image, split into 9 chunks
- 6,045,716 bytes total
- Each chunk (tile) is 1344×756
This is an imperfect test because I am not splitting a binary file. I am creating multiple independent images, so the total size increases due to compression inefficiency. Even though splitting increases total size by only 5 percent, I am seeing a 10 to 20 percent drop in performance.
From these rudimentary tests it appears that splitting the index would not improve performance.
Related issues and discussions
- Any tips for decreasing index file size?
- Use stopword lists to reduce index size and improve search results
- Search metrics
- Compensate for border radius when displaying progress bar
- Serving pre-compressed Brotli files


